行業洞察:接訴即辦平台之群體性訴求識别能力技術實現
2023-11-8
一.背景
市民熱線是市民和(hé)城(chéng)市管理(lǐ)者溝通(tōng)的(de)重要手段,市民可(kě)以通(tōng)過市民熱線對城(chéng)市管理(lǐ)相關的(de)訴求和(hé)意見進行表達,城(chéng)市管理(lǐ)者則可(kě)以通(tōng)過市民熱線了(le)解城(chéng)市管理(lǐ)中存在的(de)問題,不斷完善城(chéng)市管理(lǐ)服務。
群體性訴求是市民熱線中群衆訴求普遍性、廣泛性的(de)集中體現,最能代表當前存在的(de)社會性問題。由于群體性訴求涉及面較廣,通(tōng)常涵蓋了(le)公共服務、社會治安、環境衛生、交通(tōng)等方面的(de)訴求;來源衆多(duō),可(kě)能是來自社區、居民區、工作單位等不同人(rén)群的(de)關于公共資源、公共服務設施等方面的(de)訴求,因此僅憑坐(zuò)席員根據工作經驗進行手動标識和(hé)識别,存在耗時長、效率低、不精确等亟待解決的(de)問題。
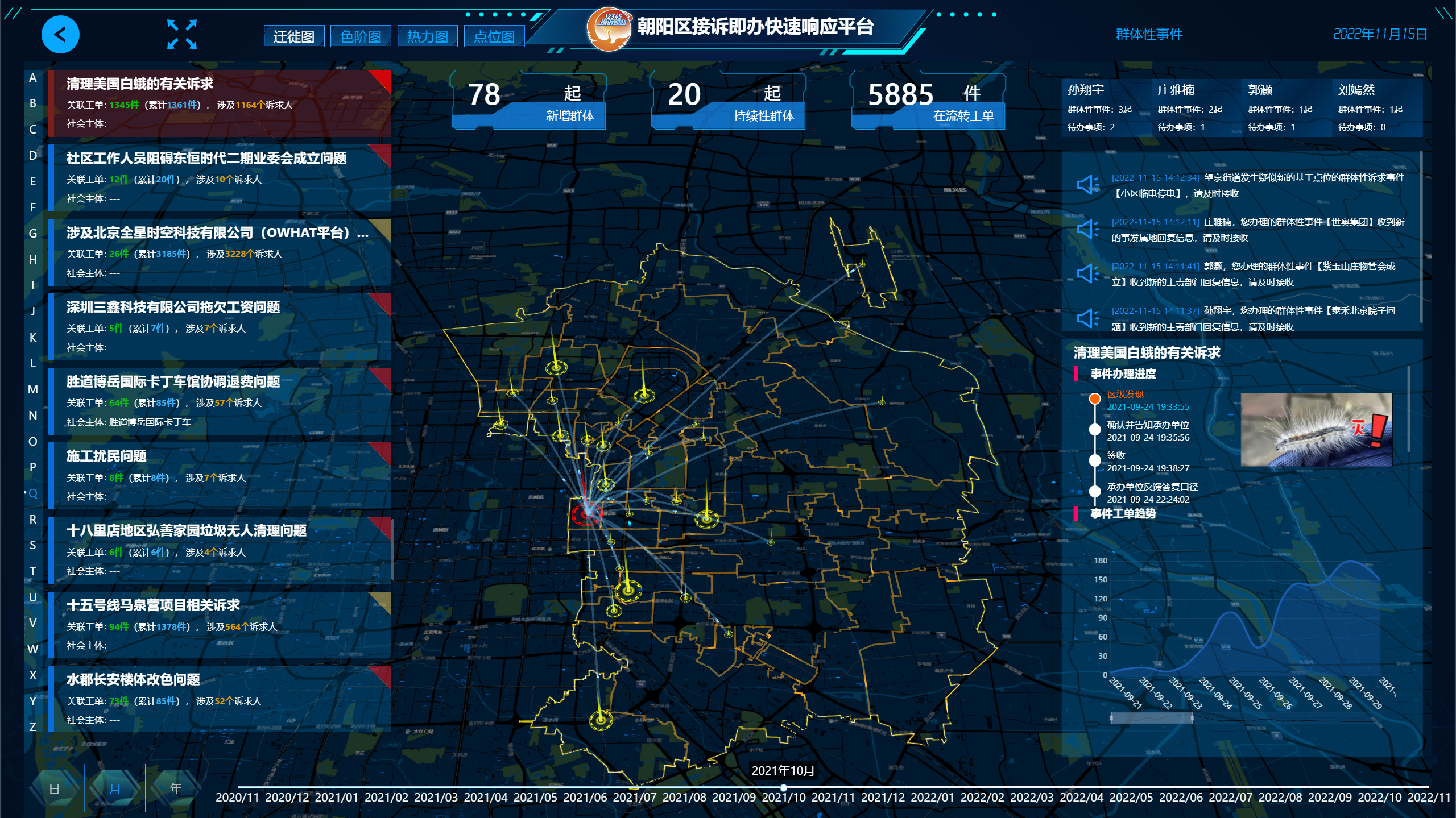
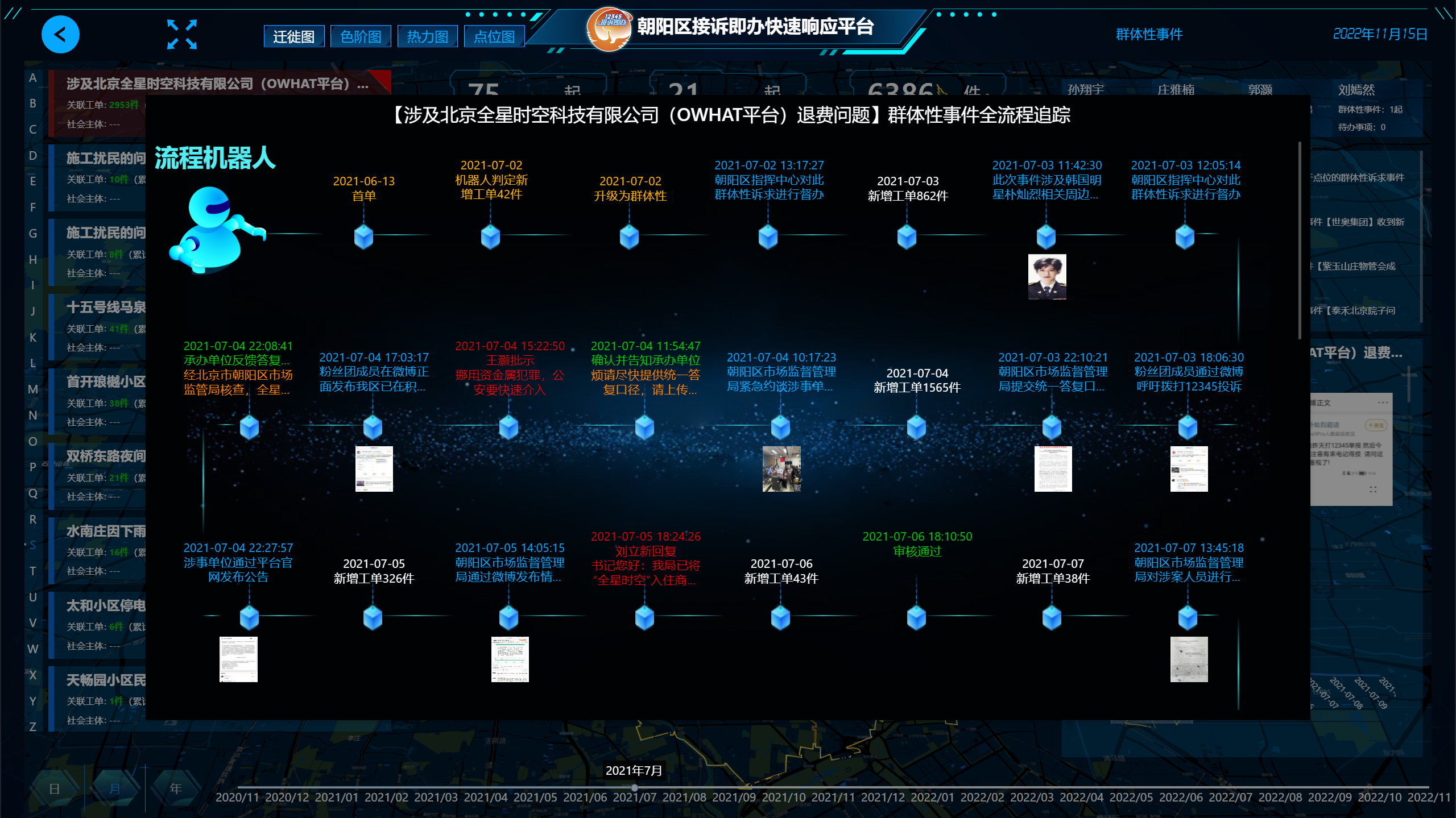
國研AI能力中台提供了(le)對于群體性訴求的(de)識别能力,該解決方案基于深度學習方法,結合客戶數據特征,實現了(le)對于相似工單的(de)聚合效果,在具體實現上利用(yòng)了(le)NER方法進行工單實體識别。下(xià)面将介紹NER方法在應用(yòng)過程中的(de)部分(fēn)細節。
二.NER方法
市民熱線的(de)工單内容長度普遍在100字至500字之間,内容結構差異大(dà),核心訴求表述方式無明(míng)顯規律可(kě)循,批量對工單内容本身識别群體性訴求效果不佳。經分(fēn)析發現,工單内容中針對被訴主體、被訴事項等信息普遍存在,因此可(kě)将對工單内容本身的(de)識别轉變爲對工單内容中關鍵實體的(de)識别,主要涉及投訴企業、投訴社區、投訴小區、投訴地址、投訴問題等實體。
三.Transformer網絡架構
NER方法即命名實體識别,可(kě)用(yòng)于完成對市民熱線工單内容中存在的(de)上述實體的(de)識别。目前結合深度學習的(de)命名實體識别任務主要基于Transformer網絡架構,其特點在于自注意力機制(Self-Attention),該機制會對每個輸入元素都與其他(tā)所有元素計算(suàn)相關性權重,然後根據這些權重對所有元素求加權平均:
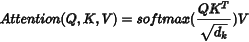
Transformer網絡結構如下(xià),其中使用(yòng)的(de)Multi-HeadAttention是對多(duō)個Attention進行組合,每個Attention學到不同的(de)輸入特征,以便提高(gāo)模型能力。
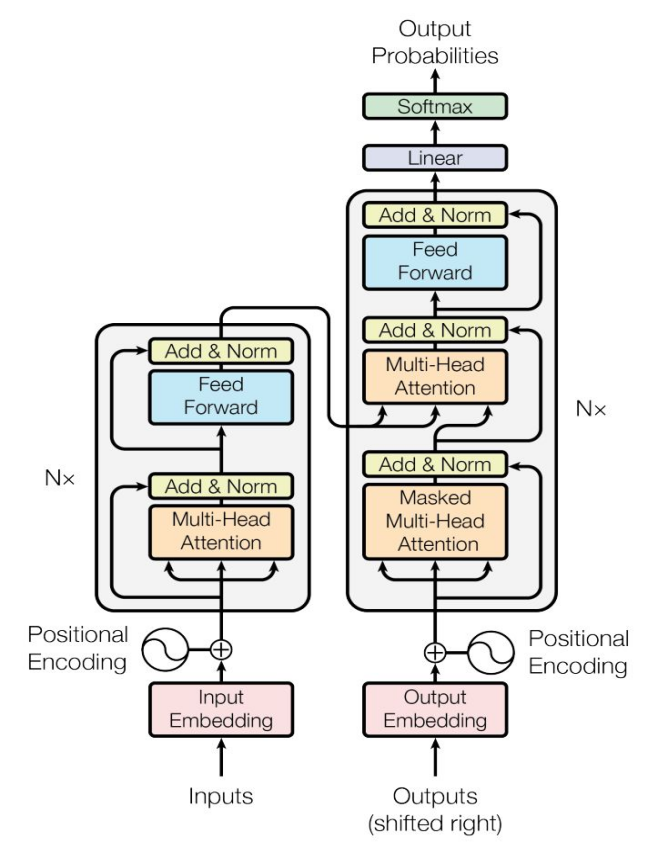
相對于傳統機器學習基于概率模型來完成NER任務,自注意力機制使得(de)每個輸入元素都可(kě)以利用(yòng)序列中其他(tā)元素的(de)信息,更好地理(lǐ)解語句的(de)上下(xià)文。
四.BERT預訓練模型
BERT模型是一個基于Transformer網絡架構的(de)預訓練模型,其Encoder層結構如下(xià),它使用(yòng)雙向的(de)TransformerEncoder來對輸入文本進行編碼,能夠更好地捕捉文本中的(de)雙向上下(xià)文信息,并且由于它是在大(dà)規模文本語料上進行的(de)無監督預訓練,能夠更好地理(lǐ)解文本表示。在訓練命名實體識别任務中,可(kě)以利用(yòng)預訓練的(de)BERT模型作爲特征提取器,對輸入内容進行編碼,再通(tōng)過微調模型的(de)方式進行訓練。
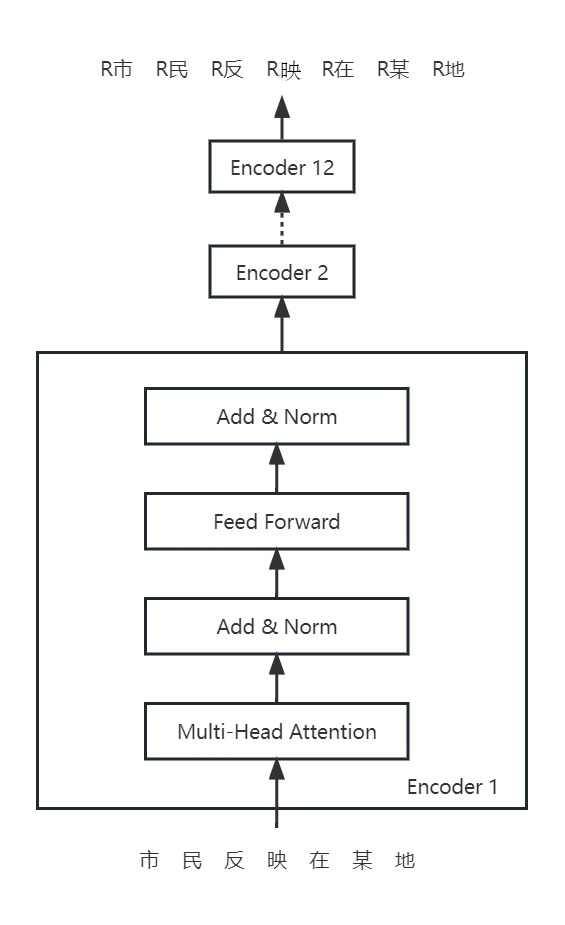
五.微調模型
由于借助了(le)預訓練模型,隻需要在少量的(de)标注數據上進行有監督訓練,就可(kě)以産出滿足特定領域的(de)NER任務模型。微調模型方式選擇在BERT模型基礎上接入FeedForwardNetwork和(hé)softmax層,同時隻允許BERT模型最上層Encoder的(de)權重參與更新,凍結其餘Encoder層權重參數。這麽做(zuò)的(de)目的(de)是考慮到BERT是基于大(dà)規模通(tōng)用(yòng)數據集訓練而來,爲了(le)在特定領域上能實現更好的(de)效果,需要将部分(fēn)Encoder層的(de)參數參與更新。在參與參數更新的(de)Encoder層的(de)選擇上,由于貼近輸入端的(de)Encoder層通(tōng)常表示通(tōng)用(yòng)語義信息,而貼近輸出端的(de)Encoder層和(hé)特定領域任務聯系更加緊密,因此更新它的(de)權重參數可(kě)以使模型整體能夠更好地适配微調任務。
六.總結
上述内容主要介紹了(le)針對市民熱線工單内容進行群體性訴求識别的(de)場景下(xià),如何應用(yòng)NER技術轉化(huà)識别過程,同時結合深度學習方法和(hé)微調預訓練模型的(de)方式,提升實體識别的(de)準确度。
群體性訴求識别能力是國研AI能力中台體系中基礎服務能力的(de)綜合體現。在國研AI中台技術體系中,除上述NER能力外,還包括自然語言處理(lǐ)方向的(de)文本分(fēn)類、關鍵詞提取以及對話引擎服務等能力。
在社會服務管理(lǐ)領域,國研軟件在技術方面已積累了(le)相當多(duō)的(de)建設經驗,同時協助用(yòng)戶在社會服務管理(lǐ)方法、手段等方面也(yě)取得(de)了(le)長足的(de)進展。未來,我們将繼續在網格化(huà)社會服務管理(lǐ)領域充分(fēn)發揮自身優勢,爲社會服務管理(lǐ)工作貢獻力量。(作者爲北(běi)京國研數通(tōng)軟件技術有限公司大(dà)數據架構師程伯瑄)